Moving Beyond .ipynb

Let’s be honest, 847 rows of cells isn’t a joke.
You start with a simple exploration in Jupyter, maybe just poking around some data to see what’s hiding in those columns. Three weeks later, you’re staring at a notebook that’s somehow grown to 847 cells, with variables scattered across dozens of code blocks, and you can’t remember which cell actually contains your final model.
The Notebook Trap (And Why We Keep Falling Into It)
Jupyter notebooks are incredible for what they were designed to do, quick experiments and rapid prototyping. They let you think out loud in code, visualize results immediately, and iterate faster than traditional scripting.
But here’s the thing, somewhere along the way, many of us started treating them like production environments.
Maybe you rerun a cell out of order and suddenly your results don’t make sense anymore. Or you accidentally overwrite a variable and spend an hour debugging why your accuracy dropped from 94% to 12%.
Before you know it, you’re dealing with hidden state issues, unreproducible results, and notebooks that only work when you run every single cell in the exact right sequence, preferably while holding your breath.
You know what’s worse? Trying to collaborate on one of these behemoths with your team, explaining to stakeholders why your “simple” analysis needs three different environments to run.
—
When Notebooks Become Technical Debt
Traditional notebook workflows often lead to what I call “analysis archaeology.” You’ve got data preprocessing mixed with model training, evaluation metrics scattered between visualization code, and configuration parameters hardcoded in random cells. The linear structure of notebooks encourages this kind of mixing, even when we know it makes everything harder to maintain.
Let me paint you a picture.
Marcus, an ML engineer at a growing fintech startup, spent two months developing a credit risk model in Jupyter. The notebook worked beautifully on his machine, clean visualizations, solid performance metrics, stakeholders nodding approvingly in demos. But when Sarah from the product team wanted to tweak a few parameters for a what, if scenario, she had to bug Marcus every single time.
And when the compliance team asked for the model to be run with last quarter’s data? That turned into a three day adventure involving environment conflicts, missing dependencies, and Marcus frantically trying to remember which cells he’d modified since the original analysis. This isn’t an edge case. This is the reality for most ML teams working with traditional notebooks.
—
The Real Cost of Notebook-Driven Development
The issue goes deeper than just messy code.
When your entire ML workflow lives in traditional notebooks, you’re inadvertently creating several bottlenecks that compound over time:
-
Collaboration becomes a bottleneck. Ever tried to let a non-technical stakeholder run your analysis? Or worse, tried to hand off a notebook to a colleague who needs to understand what you did six months ago? The context is locked in your head, and the notebook is just a series of cryptic code blocks.
-
Reproducibility turns into a myth. Good luck trying to recreate results from three months ago when your notebook depends on global state, specific data versions, and that one environment variable you set manually. Most teams just accept that “it worked on my machine” is the best they can do.
-
Iteration becomes painful. Want to test different scenarios? Run the same analysis on updated data? Each change requires careful coordination of which cells to run, in what order, with which parameters. What should be a five-minute task turns into an hour of careful cell execution.
-
Knowledge sharing hits walls. When your analysis process is trapped in notebook format, it’s nearly impossible for others to build on your work. They either have to reverse-engineer your approach or start from scratch.
—
Traditional notebooks weren’t built for this kind of collaborative analysis.
They were built for individual exploration, which is why they break down so quickly when you need to work with others or revisit work later.
This is where modern data workspaces like Livedocs start to make sense. Instead of forcing the notebook paradigm into collaboration scenarios it wasn’t designed for, they rethink what a data analysis environment should look like from the ground up.
—
Enter Livedocs: AI-Powered Analysis That Actually Scales
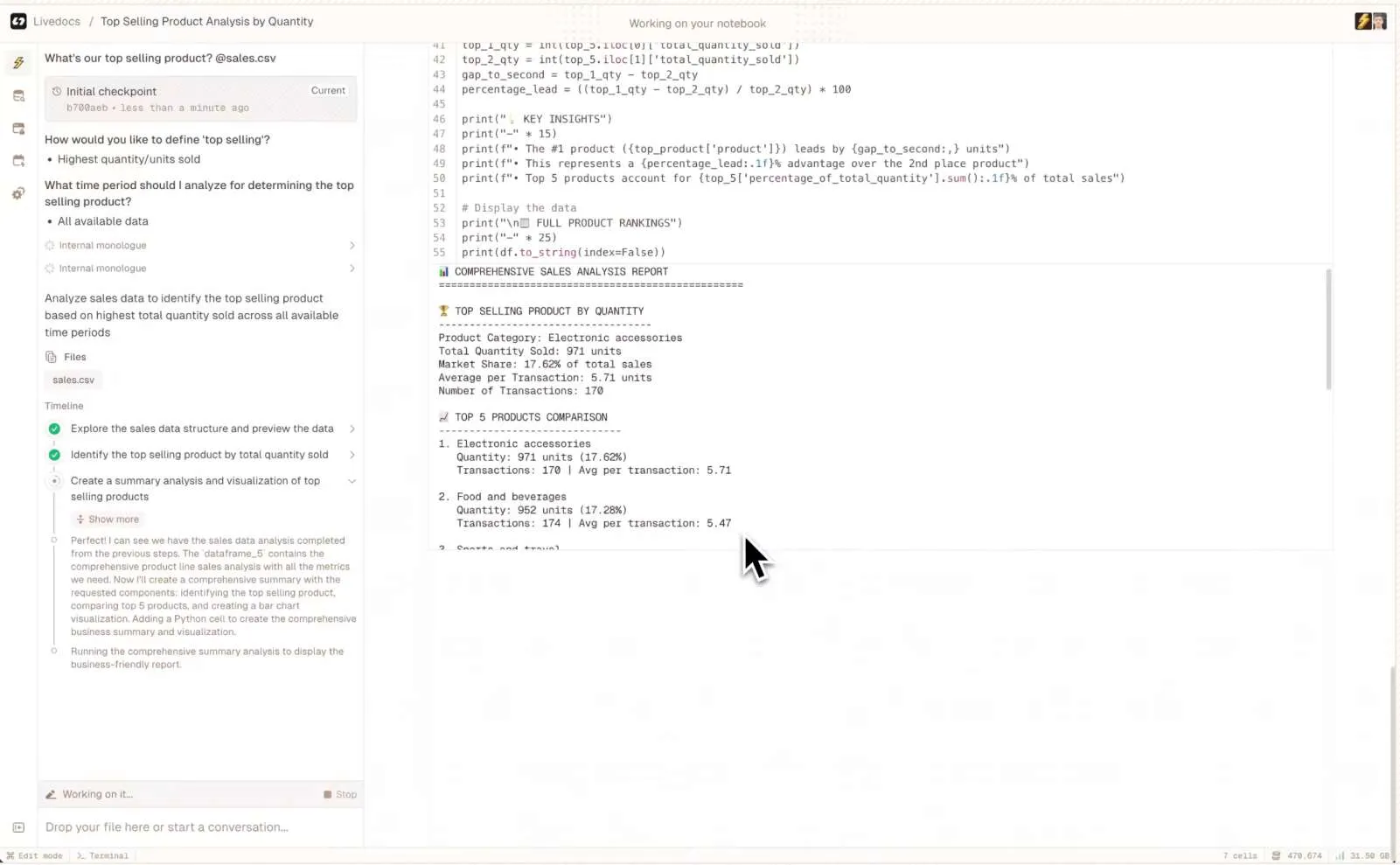
Livedocs recognized that the problem isn’t just about better notebooks, it’s about building a workspace that’s powerful enough for serious analysis but simple enough that it doesn’t get in your way.
You know how traditional notebooks force you to think linearly, even when your analysis isn’t linear? And how most BI tools require endless setup before you can do any actual analysis? Livedocs takes a different approach entirely.
The platform lets you run models, do scenario planning, perform exploratory data analysis, and even build interactive applications, all in a collaborative environment where your teammates can actually understand and modify your work.
—
The Hidden Cost of Tool Fragmentation
Here’s something most teams don’t account for: You’ve got Jupyter for exploration, maybe Databricks or Colab for bigger datasets, some BI tool for dashboards, Slack for sharing results, and Git for… well, trying to version control notebooks (good luck with that).
Modern data workspaces try to solve this by providing a unified environment where you can do serious analysis, collaborate with teammates, and share results with stakeholders—all in one place. That’s not just convenient; it’s a fundamental shift in how efficiently teams can work.
When Marcus from our earlier example moved his team to Livedocs, the biggest change wasn’t in individual productivity, it was in how quickly the team could iterate on each other’s work. Sarah could tweak parameters herself.
The compliance team could run historical scenarios without needing Marcus to babysit every execution. New team members could understand and build on existing analyses without weeks of knowledge transfer.
—
Final Thoughts
Honestly? Take a look at what Livedocs offers. Even if you don’t end up using it, understanding how modern data workspaces approach these problems will change how you think about structuring your ML workflows. The future of ML work isn’t about finding the perfect notebook, it’s about building workflows that let you focus on analysis instead of fighting with tools. Your stakeholders, your teammates, and your future self will thank you for making that shift.
The fastest way to build a live dashboard in 2026? Livedocs.
- Instant data connections
- Drag-and-drop editor
- Real-time updates
- Easy sharing
Get started with Livedocs and build your first live dashboard in minutes.
—
- 💬 If you have questions or feedback, please email directly at a[at]livedocs[dot]com
- 📣 Take Livedocs for a spin over at livedocs.com/start. Livedocs has a great free plan, with $5 per month of LLM usage on every plan
- 🤝 Say hello to the team on X and LinkedIn
Stay tuned for the next tutorial!

