GPU Cloud Providers in 2026
We’ve all been there, staring at pricing pages, trying to figure out which cloud GPU provider is suitable for your startup or leave you hanging during a critical training run. The market’s gotten messy. Really messy.
But here’s the thing: we used Livedocs to cut through the noise and analyze 11 leading providers, and honestly? The platform made what could’ve been weeks of spreadsheet hell into something you can actually understand in an afternoon.
So what did we find?
You can view the detailed notebook analysis here with this link.
The GPU Market Has Split in Half
The cloud GPU landscape in 2025 looks nothing like it did even two years ago. We’re seeing a clear bifurcation, and I mean clear, between the traditional hyperscalers (AWS, Google Cloud, Azure) and what we’re calling GPU-first providers. The latter group? They’re offering 50-70% cost savings compared to the big three.
But, and this is important, it’s not just about price. The specialized providers are innovating faster, getting access to cutting-edge hardware like the GB200 and B200 chips first, and building developer experiences that don’t require a PhD in cloud architecture to figure out.

The Numbers Tell a Story
Let’s talk dollars and cents for a second. An A100 80GB will run you around $4.10/hour on AWS. Contrast that with Lambda Labs at $1.10/hour or Vast.ai at $0.50/hour.
The math is brutal for the hyperscalers.
But here’s where things get interesting, and where Livedocs’ analysis really shines. Price-per-hour is just one variable. What about egress fees? Lambda Labs charges zero. Zilch. Nada.
If you’re iterating on models and pulling data constantly, those egress charges on AWS can exceed your compute costs. We’re talking potentially tens of thousands of dollars disappearing into network transfer fees you didn’t see coming.
InfiniBand
 You know what’s fascinating? InfiniBand support has become the dividing line between “Yeah, we do GPUs” and “We’re serious about distributed training.” If you’re training anything north of 70 billion parameters, and let’s be honest, who isn’t these days? You need InfiniBand.
You know what’s fascinating? InfiniBand support has become the dividing line between “Yeah, we do GPUs” and “We’re serious about distributed training.” If you’re training anything north of 70 billion parameters, and let’s be honest, who isn’t these days? You need InfiniBand.
The hyperscalers? AWS and Google Cloud don’t offer it at all. Azure does, but only on their specialized NDm instances. Meanwhile, Lambda Labs, CoreWeave, and RunPod include it as standard. This isn’t just a nice-to-have; it’s the difference between your multi-node training job crawling along and actually finishing before your funding round runs out.
CoreWeave deserves a special shoutout here. They’re Kubernetes-native, which means if your team already thinks in pods and deployments, you’re not learning a whole new paradigm. Plus, they’re claiming up to 35x faster performance than legacy clouds. Bold claim, but the architectural differences, particularly that InfiniBand networking.
The Developer Experience Wars Are Getting Spicy
Here’s something that doesn’t show up neatly in pricing tables: how much time you’ll waste just trying to spin up a GPU. Modal has sub-second cold starts. Sub-second. Their pure Python SDK means you literally write @stub.function(gpu=“A10”) and you’re off to the races. No YAML, no infrastructure-as-code nightmares, just Python.
RunPod’s FlashBoot technology hits 200ms cold starts and bills per-second instead of per-hour. Think about what that means for bursty inference workloads. You’re not paying for 59 minutes of idle GPU time because your job took 90 seconds.
Then there’s Together AI, which has gone all-in on inference with OpenAI, compatible APIs. Migration is basically copy-paste. They’re running GB200 NVL72 clusters, the absolute bleeding edge for trillion-parameter model inference. We’re talking 30x faster real-time performance. Those kinds of numbers change what’s economically feasible.
The Sustainability Angle
Crusoe Energy deserves mention because they’re not just ticking a corporate responsibility box. One hundred percent renewable energy for their GPU infrastructure. As AI workloads explode and people start asking hard questions about environmental impact, this isn’t just feel-good marketing, it’s becoming a competitive differentiator in enterprise procurement processes.
They’ve also got GB200 NVL72 clusters, which means you’re not sacrificing performance for sustainability. That’s… actually kind of remarkable when you think about it.
The Hyperscalers: Expensive, But…
Let me be clear, AWS, Google Cloud, and Azure aren’t losing because they’re incompetent. They’re losing on price for pure GPU compute, but they’re winning on the stuff that matters if you’re a Fortune 500 company. Compliance certifications? Check. Global presence? Check. 99.99% SLAs with actual financial penalties? Check. AWS offers 30+ regions with deep ecosystem integration. If your entire infrastructure is already living in S3, EKS, and SageMaker, the premium you pay for EC2 GPU instances might be worth it just for not having to manage cross-cloud data transfer and authentication headaches.
Google Cloud brings TPUs into the mix, their v5e and v5p offerings are genuinely different from GPU-based compute and can be fantastic for specific workloads, especially if you’re already invested in Google’s ML framework ecosystem.
Azure’s OpenAI partnership means native integration with GPT-4 and other frontier models. For enterprises building on top of LLMs rather than training their own, that’s a massive unlock.
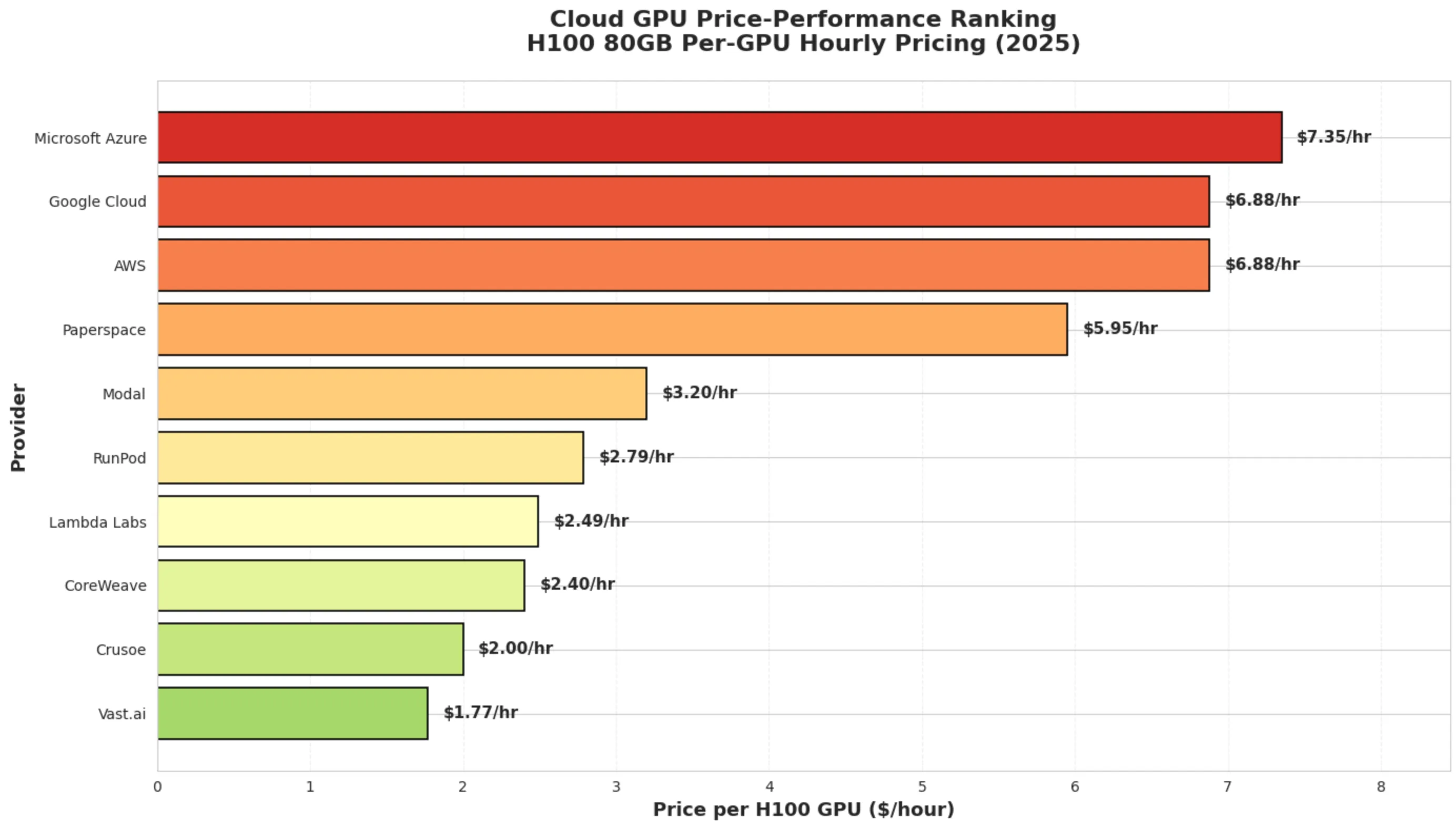 Analysis generated with Livedocs.
Analysis generated with Livedocs.
Vast.ai’s Marketplace Model
Vast.ai is the Craigslist of GPU compute (and I mean that more positively than it sounds). It’s a decentralized marketplace where you’re renting hardware from, well, anyone. Crypto miners with idle rigs, researchers with spare capacity, random people with gaming PCs.
The pricing is insane, like 5-6x cheaper than hyperscalers. You can get H100 access for prices that would make AWS blush. But, and this is a big but, there’s no SLA. Reliability is variable. Network performance is inconsistent. This is not where you run your production inference stack.
But for research? Experimentation? Training that janky LoRA you’re not sure will even work? Vast.ai is perfect. Just go in with your eyes open.
It’s All About Your Use Case
The Livedocs analysis breaks this down beautifully, but here’s the TL;DR version:
If you’re doing serious distributed training
Especially large language models, Lambda Labs or CoreWeave should be at the top of your list. Zero egress fees plus InfiniBand networking is the winning combo. Lambda’s got that sweet 50% academic discount, too, if that applies to you.
For production inference at scale
Together AI has positioned itself incredibly well. Those GB200 clusters aren’t just marketing fluff, they’re enabling real-time trillion, parameter model inference that was basically science fiction 18 months ago.
If developer velocity is your primary concern
It should be if you’re an early-stage startup, Modal or RunPod are game, changers. The friction is just… gone. You spend time on your models instead of fighting with infrastructure.
Enterprise folks with serious compliance requirements
Aren’t escaping AWS, GCP, or Azure anytime soon. The premium is real, but so are the guarantees. Sometimes you need that 99.99% SLA with teeth.
Budget-constrained researchers and experimenters
Should absolutely kick the tires on Vast.ai. Just don’t bet your company on it.
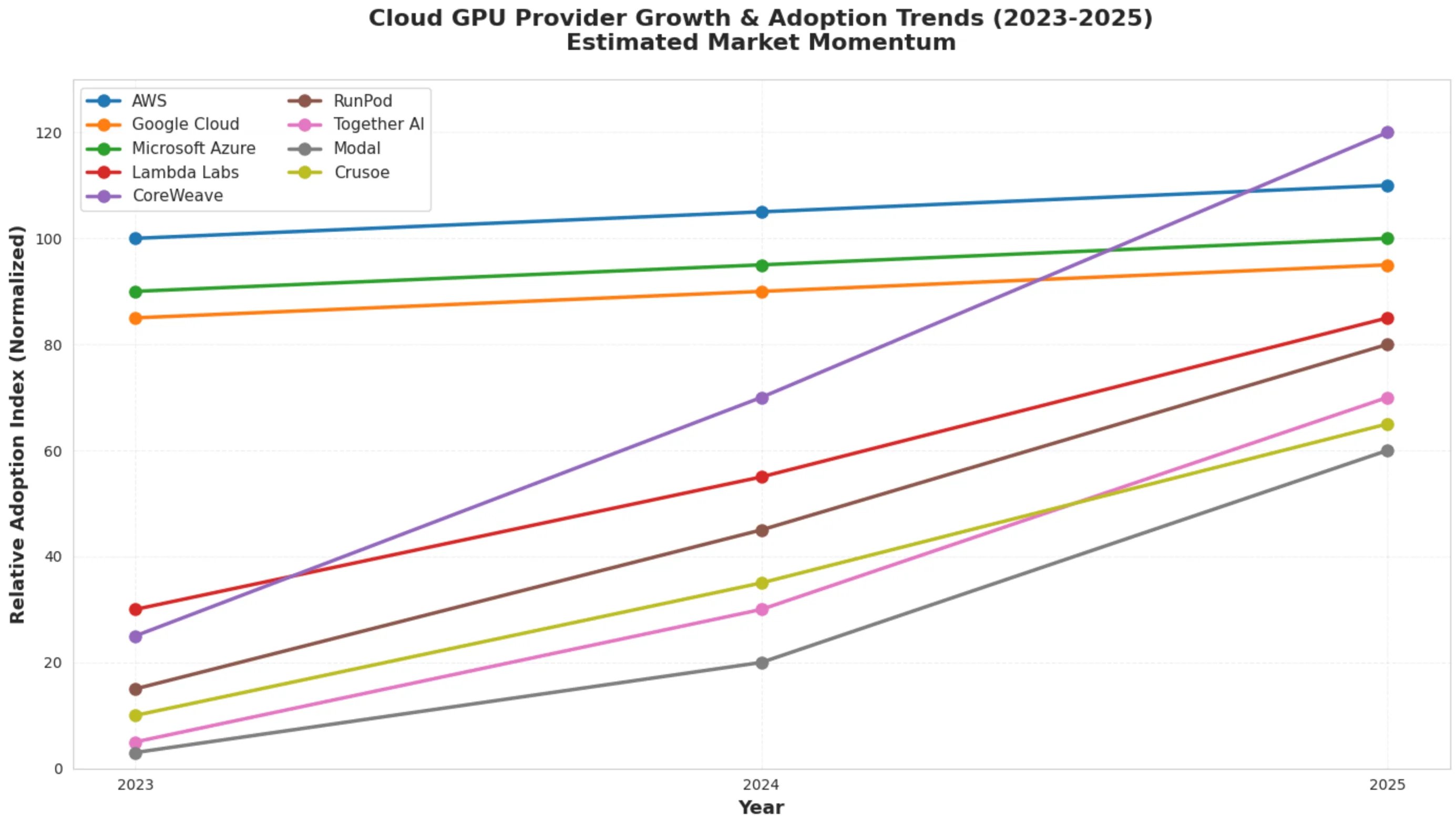 Analysis generated with Livedocs.
Analysis generated with Livedocs.
The Multi-Cloud Reality Nobody Wants to Admit
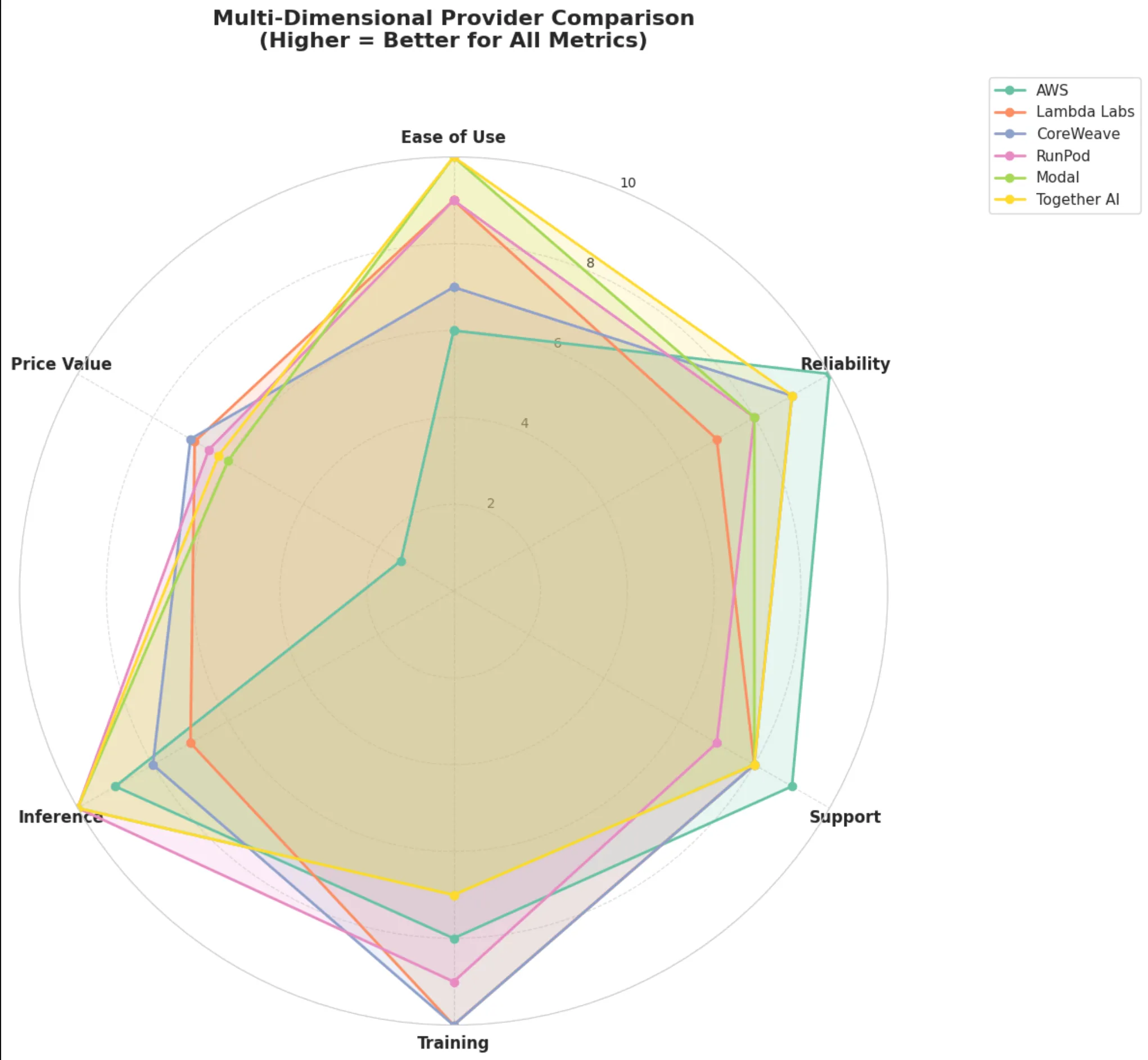 Analysis generated with Livedocs.
Analysis generated with Livedocs.
Here’s something the analysis surfaced that’s worth sitting with: the optimal strategy is probably not picking one provider and going all-in.
Different workloads have different requirements. Your training might live on Lambda Labs while your inference runs on Together AI and your model registry sits in S3.
Yeah, that’s more operational complexity. It’s also potentially saving you six figures annually while giving you best-in-class tools for each job. The cognitive overhead of managing multiple providers has dropped significantly, these platforms have matured enough that basic operations are standardized.
Questions You Should Actually Ask
The Livedocs report includes a bunch of pointed questions to ask providers during evaluation. Some highlights that really matter:
-
Egress fees and network transfer costs. Get this in writing. Get examples. Get horror stories. This is where surprise bills happen.
-
GPU availability during high-demand periods. If everyone’s training models in Q4, will you get squeezed out? What’s the reservation system look like?
-
InfiniBand support and configuration. If you need multi-node training, this is non-negotiable. Make them explain their topology.
-
Cold start times for serverless workloads. The difference between 200ms and 30 seconds is the difference between a viable product and a non-starter.
Billing granularity. Per-second versus per-hour is a big deal if your workloads are bursty.
What We Learned from Doing This Analysis in Livedocs
Coming back to the tool itself for a second, using Livedocs to compile and analyze this landscape was eye-opening. The platform lets you pull in data from multiple sources, structure it coherently, and then interrogate it in ways that static documents just… can’t.
You’re not just reading about the comparison; you’re interacting with it. Want to filter by InfiniBand support? Done. Need to see only providers with sub-$2/hour H100 pricing? Takes two seconds. The AI helps surface insights like “Hey, notice that every provider with true Kubernetes-native architecture also has InfiniBand?” That’s not random, that’s signal.
For anyone doing competitive analysis, market research, or just trying to make sense of complex technical choices, Livedocs changes the game. The old model of someone spending two weeks building a static deck that’s outdated before the final review meeting? That’s done. This is living documentation that evolves as the market evolves.
Final Thoughts
The cloud GPU market in 2025 is healthier than it’s ever been, precisely because it’s fragmented. Competition is forcing innovation. Pricing is becoming more rational. Developer experience is improving across the board.
If I had to make a betm and we’re placing bets with actual money here, I’d say the GPU-first providers are going to continue winning from hyperscalers on pure compute workloads. The gap is just too wide.
Meanwhile, the hyperscalers will increasingly position themselves as platforms for orchestration, governance, and integration rather than raw GPU rental.
To make your own analysis like this? Use [Livedocs](https://www.[Livedocs](https://www.livedocs.com).com).
- 8x speed response
- Ask agent to find datasets for you
- Set system rules for agent
- Collaborate
- And more
Get started with [Livedocs](https://www.[Livedocs](https://www.livedocs.com).com) and build your first live notebook in minutes.
- 💬 If you have questions or feedback, please email directly at a[at]Livedocs[dot]com
- 📣 Take Livedocs for a spin over at [Livedocs.com/start](https://Livedocs.com/start). [Livedocs](https://www.[Livedocs](https://www.livedocs.com).com) has a great free plan, with $10 per month of LLM usage on every plan
- 🤝 Say hello to the team on X and LinkedIn
Stay tuned for the next article!
Analysis current as of November 2025. GPU provider landscape changes rapidly—always verify current pricing and availability. Use Livedocs to keep your own analysis updated in real-time
Ready to analyze your data?
Upload your CSV, spreadsheet, or connect to a database. Get charts, metrics, and clear explanations in minutes.
No signup required — start analyzing instantly

