Complete Guide: Beginners EDA
Here’s something they don’t tell you in data science courses: you’ll spend way more time understanding your data than building fancy models. Maybe 30%, maybe 50%, some weeks it feels like all you do is poke around datasets trying to figure out what’s actually going on.
And you know what? That’s exactly where you should be spending your time.
This guide will walk you through the entire EDA process in Python, from your first look at a raw dataset to the moment you genuinely understand what story the data is trying to tell you. We’ll cover the manual techniques that build intuition, the automated tools that save hours, and the thinking process that separates good analysis from checkbox exercises.
What Actually Is Exploratory Data Analysis?
Before we write a single line of code, let’s talk about what EDA really means. Because it’s not just running a bunch of commands and looking at charts.
EDA is systematic curiosity about your data. It’s the process of asking questions, checking assumptions, and building an understanding of what you’re working with before you try to extract insights or build models. You’re looking for patterns, relationships, outliers, mistakes, and anything unexpected that changes how you approach the problem.
Think of it this way: if you’re analyzing customer churn data, EDA is where you discover that “monthly charges” has 200 rows with negative values (impossible), that 15% of your data is missing (problem), and that customers who’ve been with you more than 3 years almost never churn (insight). Miss those details, and your churn prediction model is built on sand.
The goal is to genuinely understand your data’s structure, quality, and story.
Setting Up Your Python Environment
But first, let’s open up a Livedocs document and install few libraries:
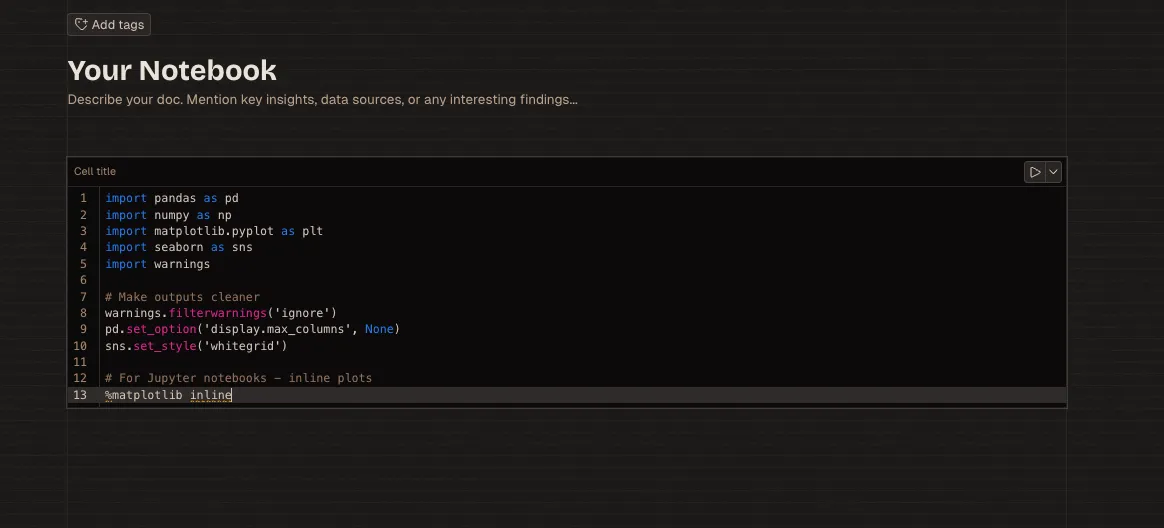
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
# Make outputs cleaner
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
sns.set_style('whitegrid')
# For Jupyter notebooks - inline plots
%matplotlib inline
Pandas handles data manipulation and provides the DataFrame structure you’ll work with constantly. NumPy powers numerical operations behind the scenes. Matplotlib and Seaborn create visualizations—Matplotlib for control, Seaborn for beauty.
These four libraries cover probably 80% of what you’ll do during EDA. The remaining 20% involves specialized tools we’ll get to later.
Loading and First Impressions
Every EDA journey starts the same way: loading data and taking that crucial first look.
# Load your dataset
df = pd.read_csv('your_data.csv')
# First glance
print(df.head())
The .head() function shows your first five rows. But here’s what you’re really looking for during this first impression:
- Do the column names make sense? Are they readable, or are you looking at cryptic codes like “Col_A_23_rev2”? Clear column names matter more than you think.
- What types of data do you see? Numbers, text, dates, categories? This shapes your entire analysis approach.
- Are there obvious issues? Missing values showing as “N/A” or weird placeholders like 999999? Catch these early.
- Does the data structure match expectations? If you’re expecting customer data, do the rows represent individual customers, or are they transactions that need grouping?
Let’s get more specific information:
# Dataset dimensions
print(f"Rows: {df.shape[0]}, Columns: {df.shape[1]}")
# Column names as a list
print(df.columns.tolist())
# Data types and memory usage
print(df.info())
# Quick statistical summary
print(df.describe())
The .info() method is underrated. It shows you data types, non-null counts, and memory usage. If you’re expecting 10,000 rows but a column only has 7,500 non-null entries, you’ve got missing data to investigate.
The .describe() output gives you statistics for numerical columns: mean, standard deviation, min, max, quartiles. Spot-check these. If “age” has a max value of 250, something’s wrong. If “price” has a negative minimum, you’ve got data quality issues.
Understanding Your Data Types
Not all columns are created equal. How you analyze data depends entirely on its type.
# Check data types
print(df.dtypes)
# Count different types
print(df.dtypes.value_counts())
# Identify numerical and categorical columns
numerical_cols = df.select_dtypes(include=['int64', 'float64']).columns
categorical_cols = df.select_dtypes(include=['object', 'category']).columns
print(f"Numerical columns: {list(numerical_cols)}")
print(f"Categorical columns: {list(categorical_cols)}")
Here’s where things get interesting. Sometimes Pandas guesses wrong. A column might be imported as object (string) when it should be numerical, or dates might be strings instead of datetime objects.
Pro tip: Check columns that should be numbers but aren’t:
# Check what's preventing numerical conversion
for col in df.columns:
if df[col].dtype == 'object':
try:
pd.to_numeric(df[col])
except ValueError as e:
print(f"{col}: {e}")
This reveals issues like commas in numbers (“1,000” instead of 1000) or rogue text values in numerical columns.
The Missing Data
Missing data is rarely random. The pattern of missingness often tells you something important about your data collection process or the underlying phenomenon.
# Count missing values
missing = df.isnull().sum()
missing_pct = (df.isnull().sum() / len(df)) * 100
missing_df = pd.DataFrame({
'Column': missing.index,
'Missing_Count': missing.values,
'Percentage': missing_pct.values
})
# Show only columns with missing data
print(missing_df[missing_df['Missing_Count'] > 0].sort_values('Missing_Count', ascending=False))
But don’t just count, visualize the pattern:
# Heatmap of missing data
plt.figure(figsize=(12, 6))
sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis')
plt.title('Missing Data Pattern')
plt.show()
This heatmap reveals whether missing data is random or structured. If you see vertical stripes (entire columns mostly missing), that’s different from scattered dots (random missingness) or horizontal patterns (certain rows missing many values).
Ask yourself:
- Is data missing completely at random (MCAR)?
- Is it missing at random but related to other variables (MAR)?
- Is it missing not at random—meaning the missingness itself is meaningful (MNAR)?
For example, if income data is more likely to be missing for certain age groups, that’s MAR. If wealthy people are more likely to not report income, that’s MNAR. This distinction affects how you handle it later.
Detecting Duplicate Records
Duplicates corrupt analysis. They bias statistics, inflate counts, and break models.
# Check for complete duplicates
duplicates = df.duplicated().sum()
print(f"Duplicate rows: {duplicates}")
# View the duplicates
if duplicates > 0:
print(df[df.duplicated(keep=False)])
# Check for duplicates in specific columns
# (like customer ID should be unique)
id_duplicates = df.duplicated(subset=['customer_id']).sum()
print(f"Duplicate customer IDs: {id_duplicates}")
Sometimes duplicates are obvious, identical rows repeated. Other times they’re subtle—same customer with slightly different spellings or timestamps.
Univariate Analysis: One Variable at a Time
Now we get into actual exploration. Univariate analysis means examining each variable individually to understand its distribution, central tendency, and spread.
Numerical Variables
For continuous numerical data, start with visualizations:
# Histogram
plt.figure(figsize=(10, 6))
plt.hist(df['age'], bins=30, edgecolor='black', alpha=0.7)
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
# Box plot (reveals outliers)
plt.figure(figsize=(8, 6))
sns.boxplot(y=df['age'])
plt.title('Age Box Plot')
plt.show()
# Distribution plot with KDE (kernel density estimate)
plt.figure(figsize=(10, 6))
sns.histplot(df['age'], kde=True, bins=30)
plt.title('Age Distribution with KDE')
plt.show()
What you’re looking for: Distribution shape: Is it normal (bell curve), skewed left or right, bimodal (two peaks), or something else entirely? This affects which statistical methods you can use later.
Outliers: Box plots make these visible immediately. Those dots beyond the whiskers? Investigate them. Are they errors or legitimate extreme values?
Range and spread: Does the data span a reasonable range? If analyzing apartment prices and seeing values from $100 to $100 million, you’ve got issues (or you’re including both closets and penthouses).
For each numerical variable, calculate key statistics:
# Detailed statistics for a column
col = 'income'
print(f"Mean: {df[col].mean():.2f}")
print(f"Median: {df[col].median():.2f}")
print(f"Std Dev: {df[col].std():.2f}")
print(f"Min: {df[col].min():.2f}")
print(f"Max: {df[col].max():.2f}")
print(f"Skewness: {df[col].skew():.2f}")
print(f"Kurtosis: {df[col].kurtosis():.2f}")
Skewness tells you about asymmetry. Positive skew means a long tail to the right (common with income data—most people earn moderate amounts, few earn millions). Negative skew is the opposite.
Kurtosis measures how heavy the tails are compared to normal distribution. High kurtosis means more outliers.
Categorical Variables
For categorical data, you care about frequency and proportions:
# Value counts
print(df['category'].value_counts())
# Proportions
print(df['category'].value_counts(normalize=True))
# Bar plot
plt.figure(figsize=(10, 6))
df['category'].value_counts().plot(kind='bar')
plt.title('Category Distribution')
plt.xlabel('Category')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.show()
Watch for:
Imbalanced categories: If you’re predicting fraud and 99.8% of transactions are legitimate, you’ve got class imbalance that’ll wreck naive models.
Unexpected values: Categories that shouldn’t exist (“Unknown”, “N/A”, “Other” dominating) suggest data quality issues.
Cardinality: Too many unique categories (like 500 different product types) might need grouping for practical analysis.
Bivariate Analysis: Relationships Between Variables
This is where insights start emerging. You’re not just describing individual variables anymore, you’re uncovering how they relate to each other.
Numerical vs Numerical
Scatter plots and correlations:
# Scatter plot
plt.figure(figsize=(10, 6))
plt.scatter(df['hours_studied'], df['exam_score'], alpha=0.5)
plt.title('Study Hours vs Exam Score')
plt.xlabel('Hours Studied')
plt.ylabel('Exam Score')
plt.show()
# Calculate correlation
correlation = df['hours_studied'].corr(df['exam_score'])
print(f"Correlation: {correlation:.3f}")
Correlation coefficients range from -1 to +1. Values near +1 mean strong positive relationship (one increases, other increases). Near -1 means strong negative relationship. Near 0 means little linear relationship.
But here’s the thing, correlation isn’t causation, and it only measures linear relationships. Two variables could have a strong curved relationship that correlation misses entirely.
Categorical vs Numerical
Box plots and violin plots show distributions across categories:
# Box plot by category
plt.figure(figsize=(12, 6))
sns.boxplot(x='department', y='salary', data=df)
plt.title('Salary by Department')
plt.xticks(rotation=45)
plt.show()
# Violin plot (shows full distribution shape)
plt.figure(figsize=(12, 6))
sns.violinplot(x='department', y='salary', data=df)
plt.title('Salary Distribution by Department')
plt.xticks(rotation=45)
plt.show()
This reveals whether groups differ meaningfully. If engineering salaries center around $100K and marketing around $70K, that’s important for your analysis.
Categorical vs Categorical
Cross-tabulations and stacked bar charts:
# Cross-tabulation
crosstab = pd.crosstab(df['gender'], df['department'])
print(crosstab)
# Normalized (shows proportions)
crosstab_norm = pd.crosstab(df['gender'], df['department'], normalize='index')
print(crosstab_norm)
# Stacked bar chart
crosstab.plot(kind='bar', stacked=True, figsize=(10, 6))
plt.title('Department by Gender')
plt.ylabel('Count')
plt.legend(title='Department')
plt.show()
This reveals patterns like “80% of engineers are male” or “customer service is 60% female”—facts that might matter for your analysis context.
Multivariate Analysis: The Big Picture
Once you understand pairwise relationships, look at multiple variables together.
Correlation Matrix
A heatmap showing all correlations at once:
# Calculate correlation matrix
correlation_matrix = df.select_dtypes(include=[np.number]).corr()
# Heatmap
plt.figure(figsize=(14, 10))
sns.heatmap(correlation_matrix, annot=True, fmt='.2f',
cmap='coolwarm', center=0,
square=True, linewidths=1)
plt.title('Correlation Heatmap')
plt.show()
Look for dark red (strong positive correlation) and dark blue (strong negative correlation). Light colors mean weak relationships.
Pro insight: When two independent variables are highly correlated with each other (multicollinearity), that’s a problem for regression models. They’re essentially measuring the same thing.
Pair Plots
See all pairwise relationships at once:
# Pair plot (warning: slow with many columns)
sns.pairplot(df[['age', 'income', 'hours_worked', 'satisfaction']],
diag_kind='kde')
plt.show()
# With color by category
sns.pairplot(df[['age', 'income', 'hours_worked', 'satisfaction', 'department']],
hue='department')
plt.show()
This creates a matrix of scatter plots. Diagonal shows distributions, off-diagonal shows relationships between pairs. Colored by category (like department), you can see if relationships differ across groups.
Outlier Detection and Handling
Outliers mess everything up. But not all outliers are errors, some are legitimate extreme values that tell important stories.
Statistical Methods
IQR (Interquartile Range) Method:
def find_outliers_iqr(data, column):
Q1 = data[column].quantile(0.25)
Q3 = data[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = data[(data[column] < lower_bound) | (data[column] > upper_bound)]
return outliers, lower_bound, upper_bound
outliers, lower, upper = find_outliers_iqr(df, 'income')
print(f"Outliers found: {len(outliers)}")
print(f"Lower bound: {lower}, Upper bound: {upper}")
Z-Score Method:
from scipy import stats
def find_outliers_zscore(data, column, threshold=3):
z_scores = np.abs(stats.zscore(data[column].dropna()))
outliers = data[z_scores > threshold]
return outliers
outliers = find_outliers_zscore(df, 'income')
print(f"Outliers (Z-score > 3): {len(outliers)}")
What To Do With Outliers
This depends on whether they’re errors or legitimate extremes:
- If they’re errors: Remove them or impute reasonable values.
- If they’re legitimate: Keep them, but consider robust methods that aren’t sensitive to outliers (like median instead of mean), or transform the data (log transformation often helps with right-skewed data that has extreme values).
- Never automatically delete outliers without investigating why they exist.
Time Series Considerations
If your data involves time, EDA requires special attention.
# Convert to datetime if needed
df['date'] = pd.to_datetime(df['date'])
# Set as index for time series operations
df_ts = df.set_index('date')
# Plot time series
plt.figure(figsize=(14, 6))
df_ts['sales'].plot()
plt.title('Sales Over Time')
plt.ylabel('Sales')
plt.show()
# Check for trends
plt.figure(figsize=(14, 6))
df_ts['sales'].rolling(window=30).mean().plot(label='30-day Moving Average')
df_ts['sales'].plot(alpha=0.3, label='Daily Sales')
plt.title('Sales Trend')
plt.legend()
plt.show()
# Seasonality check
df_ts.groupby(df_ts.index.month)['sales'].mean().plot(kind='bar')
plt.title('Average Sales by Month')
plt.xlabel('Month')
plt.ylabel('Average Sales')
plt.show()
Look for:
- Trends: Overall upward or downward movement over time
- Seasonality: Regular patterns that repeat (daily, weekly, yearly)
- Outliers: Sudden spikes or drops that need explanation
- Stationarity: Whether the statistical properties change over time (matters for forecasting)
Feature Engineering During EDA
EDA often reveals opportunities for better features:
# Create age groups from continuous age
df['age_group'] = pd.cut(df['age'],
bins=[0, 18, 35, 50, 65, 100],
labels=['<18', '18-35', '36-50', '51-65', '65+'])
# Extract datetime features
df['hour'] = df['timestamp'].dt.hour
df['day_of_week'] = df['timestamp'].dt.dayofweek
df['is_weekend'] = df['day_of_week'].isin([5, 6]).astype(int)
# Interaction features
df['price_per_sqft'] = df['price'] / df['square_feet']
# Log transformation for skewed data
df['log_income'] = np.log1p(df['income']) # log1p handles zeros
# Encoding categorical variables
df_encoded = pd.get_dummies(df, columns=['category'], drop_first=True)
During EDA, you’re constantly asking: “What features would make this relationship clearer?” or “How can I represent this information better?”
Common EDA Pitfalls to Avoid
Let me save you some frustration by sharing mistakes I’ve seen (and made):
Trusting the first summary without checking:
.describe() shows you statistics, but doesn’t show you if data is actually valid. A mean income of $75K looks fine until you realize it includes entries where income is “unknown” coded as 999999.
Ignoring data types:
A column of zip codes might load as integers. Technically correct, but you’ll try to calculate the mean zip code (meaningless) if you’re not careful.
Forgetting to check scales:
If comparing variables, are they on similar scales? Mixing percentages (0-100) with raw counts (0-100,000) distorts visualizations and correlations.
Over-relying on automation:
The automated tools are excellent, but they can’t tell you what makes sense in your specific domain. Only you know if a negative account balance is possible or if certain customer segments should exist.
Analyzing without business context:
Pure statistical analysis might flag something as an outlier that’s actually normal in your industry. Talk to domain experts during EDA.
Stopping at visualization:
Making a chart doesn’t equal understanding. Ask why the pattern exists, what it means, and what you should do about it.
When Is EDA Actually Done?
EDA is never fully “done” in the sense of checking every possible combination. You could analyze forever.
EDA is done when you can confidently answer these questions:
- Data quality: What’s the quality of my data? Missing values, errors, inconsistencies?
- Structure: How is the data structured? What do rows and columns represent?
- Distributions: What do individual variables look like?
- Relationships: How do variables relate to each other and to my target (if I have one)?
- Anomalies: Are there outliers, unexpected patterns, or strange groupings?
- Assumptions: Do my initial assumptions about the data hold true?
- Next steps: What cleaning, transformation, or feature engineering do I need before modeling?
If you can answer those, you’re ready to move forward.
The Modern EDA Workflow: Bringing It All Together
Here’s what a complete EDA workflow actually looks like in 2026:
# 1. Load and first impressions
df = pd.read_csv('data.csv')
print(df.head())
print(df.info())
print(df.describe())
# 2. Quick automated overview
from ydata_profiling import ProfileReport
profile = ProfileReport(df, minimal=True)
profile.to_file('quick_profile.html')
# 3. Check data quality
print("Missing data:\n", df.isnull().sum())
print("\nDuplicates:", df.duplicated().sum())
# 4. Identify column types
numerical = df.select_dtypes(include=[np.number]).columns
categorical = df.select_dtypes(include=['object']).columns
# 5. Univariate analysis on key variables
for col in numerical:
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.hist(df[col].dropna(), bins=30)
plt.title(f'{col} Distribution')
plt.subplot(1, 3, 2)
sns.boxplot(y=df[col])
plt.title(f'{col} Box Plot')
plt.subplot(1, 3, 3)
stats.probplot(df[col].dropna(), dist="norm", plot=plt)
plt.title(f'{col} Q-Q Plot')
plt.tight_layout()
plt.show()
# 6. Bivariate analysis
correlation = df[numerical].corr()
plt.figure(figsize=(12, 8))
sns.heatmap(correlation, annot=True, fmt='.2f', cmap='coolwarm')
plt.title('Correlation Matrix')
plt.show()
# 7. Target analysis (if applicable)
if 'target' in df.columns:
for col in numerical:
plt.figure(figsize=(10, 6))
sns.boxplot(x='target', y=col, data=df)
plt.title(f'{col} by Target')
plt.show()
# 8. Document findings and next steps
Why Livedocs Changes the Game
Now, everything I’ve shown you is the traditional approach—write code, generate outputs, interpret results. It works, and it builds essential data intuition.
But here’s a different way to think about EDA in 2026: what if you could just ask your data questions?
This is where tools like Livedocs become genuinely interesting. Instead of writing code to calculate statistics, create visualizations, and check correlations, you can prompt an AI that understands your actual data:
- “Show me the distribution of customer ages and flag any outliers.”
- “How does purchase amount correlate with customer tenure?”
- “Compare demographics between churned and active customers.”
The AI writes the code, executes it, and presents results, all in a collaborative notebook environment where your entire team can work simultaneously. Non-technical stakeholders can ask questions and get answers without learning pandas syntax.
Does this replace understanding EDA fundamentals? Absolutely not. You still need to know what questions to ask, how to interpret results, and when something doesn’t look right. But it dramatically reduces the friction between curiosity and insight.
Traditional Python EDA: you implement what you already know to check. AI-assisted EDA in Livedocs: you explore faster, check more hypotheses, and spend less time on boilerplate code.
For teams that need to move quickly, for analysts who want to focus on insights rather than syntax, for collaborative environments where not everyone codes—it’s a meaningful shift in how EDA actually gets done.
Final Thoughts
The technical skills matter: knowing how to calculate correlations, create visualizations, detect outliers. But the thinking matters more. Asking “why is this column half missing?” or “does this relationship make sense?” or “what am I not seeing?”—that’s what separates thorough EDA from checkbox exercises.
But remember: the best EDA happens when you combine technical capability with domain knowledge and genuine curiosity.
The best, fastest agentic notebook 2026? Livedocs.
- 8x speed response
- Ask agent to find datasets for you
- Set system rules for agent
- Collaborate
- And more
Get started with Livedocs and build your first live notebook in minutes.
- 💬 If you have questions or feedback, please email directly at a[at]livedocs[dot]com
- 📣 Take Livedocs for a spin over at livedocs.com/start. Livedocs has a great free plan, with $10 per month of LLM usage on every plan
- 🤝 Say hello to the team on X and LinkedIn
Stay tuned for the next tutorial!
Ready to analyze your data?
Upload your CSV, spreadsheet, or connect to a database. Get charts, metrics, and clear explanations in minutes.
No signup required — start analyzing instantly

