Data Analysis: GPT 5.1 or Claude 4.5?

We’ve spent years arguing about which AI is “smarter,” but we rarely ask which one actually gets the job done better. And honestly, that’s the question that matters when you’re staring at a spreadsheet with hundreds of rows of sales data and no idea where to go or how to handle it.
So we did some comparisons: We threw the exact same sales dataset at both GPT-5.1 and Claude 4.5 to see how they’d handle a real-world analysis. Same data, same question, completely different approaches. The results? Well, let’s just say it got interesting fast.
The Setup: One Dataset, Two AI Models
Here’s the scenario, a company’s sales data from January 1st through February 19th, 2025. Fifty days of revenue numbers, marketing spend, regional breakdowns, and product performance. The kind of dataset that’s simple enough to understand but messy enough to reveal what these AI models are really made of.
I used Livedocs to run both analyses, if you haven’t checked it out, it’s basically a platform that lets you generate data analysis notebooks using different AI models. Think of it as your AI-powered data playground where you can actually compare how different models think. But more on that later.
The question I posed was straightforward: analyze this sales data and tell me what’s going on with the revenue drops.
GPT-5.1’s Approach
GPT-5.1 came out swinging with what I’d call a “targeted investigation” strategy. It zeroed in on one specific period, January 24-29, it is super clear on the first step and what it is going to do. The analysis broke down the data into three clean periods:
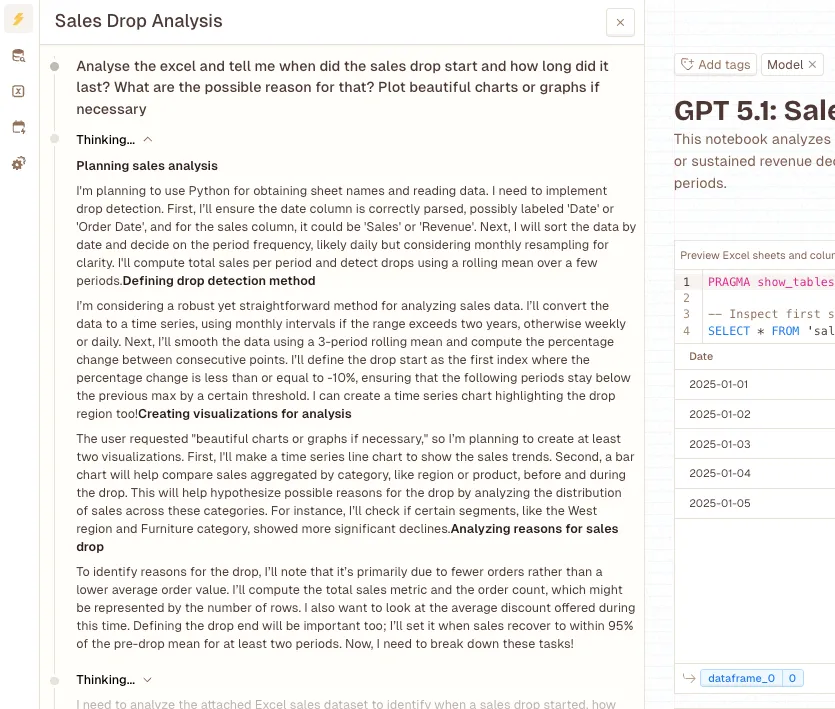
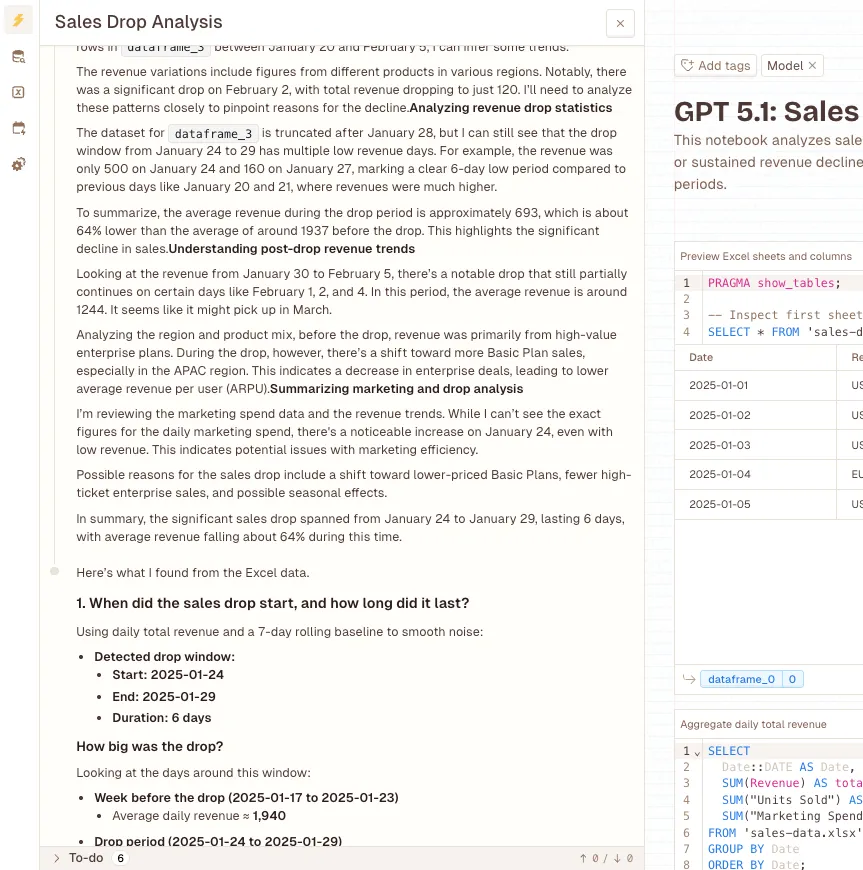
- Before the drop (Jan 17-23): Average daily revenue of $1,937.14
- During the drop (Jan 24-29): Revenue crashed to $591.67 per day
- After the drop (Jan 30-Feb 5): Recovering at $1,031.43 daily
That’s a 69% revenue decline, by the way.
The approach was focused, maybe even elegant in its simplicity.
Claude 4.5’s Game Plan: The Statistical Deep Dive
Claude took a completely different path, the “let’s look at everything” approach. Where GPT-5.1 picked one week to examine, Claude identified 20 separate days with significant revenue problems across the entire dataset.
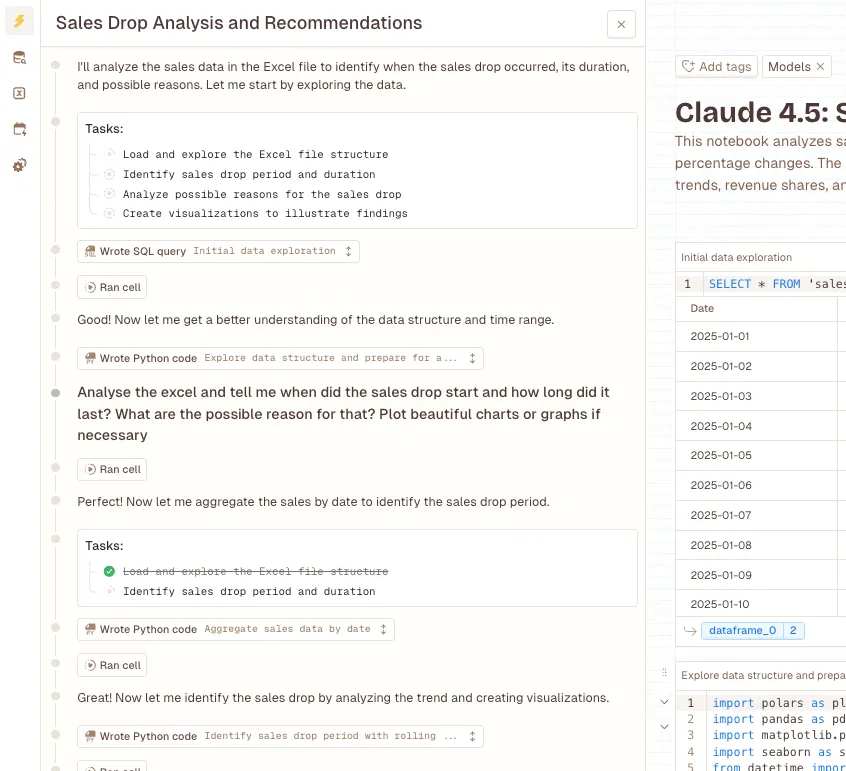
The methodology here was more statistically rigorous:
- Calculated 3-day and 7-day moving averages
- Computed percentage changes day-over-day
- Set a threshold using mean minus 0.5 standard deviations ($1,060.93)
- Flagged any day below that line as problematic
The results painted a broader picture. Claude found drops ranging from -39% all the way to -85%. Some days, revenue absolutely cratered, down to just $120. That first problematic day? January 4th, way before GPT’s identified drop period.
And here’s what stood out: Claude’s code actually ran clean. No errors, proper visualizations generated, everything executed smoothly. It’s the difference between a rough draft and a polished report.
The Strength of Each
Let me explain what’s really happening here, because this gets at something deeper about how these AI models “think.”
GPT-5.1 is a pattern matcher. It’s looking for the obvious story, that dramatic six-day period where everything went sideways. It’s intuitive, focused, and when it works, it gives you exactly what most managers want: a clear answer with a clear timeframe. “Here’s when things went wrong.”
But that focus comes with blindspots. By concentrating on one period, GPT-5.1 missed the broader context. Those 20 problem days Claude found? They tell a different story, one where the sales issues weren’t a single event but an ongoing struggle.
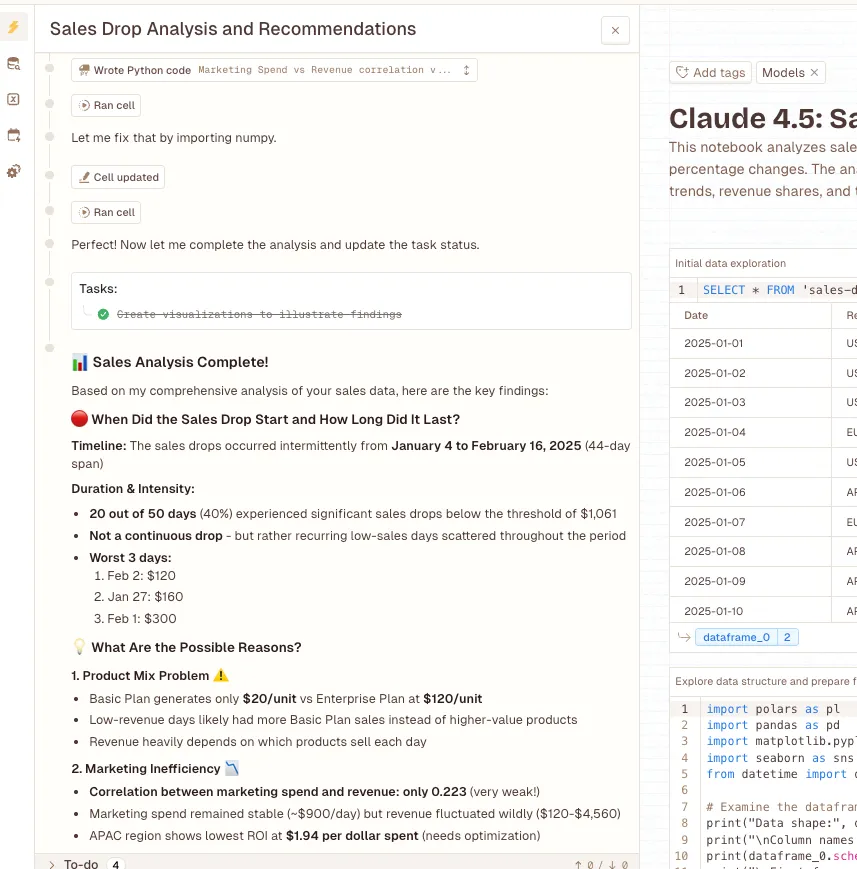
Claude 4.5 is a systematic analyst. It’s basically that colleague who always wants to “run the numbers” before making any conclusions. More comprehensive, more statistically sound, but also… well, it gives you 20 data points instead of one clean narrative.
The technical execution difference is notable too. Claude’s cleaner code suggests more robust data handling under the hood. When you’re working with real business data (which is always messier than you expect), that reliability matters.
So Which One Should You Actually Use?
Here’s where it gets practical. Neither model is “better”, they’re built for different situations.
Choose GPT-5.1 when:
- You need a quick, focused answer for stakeholders
- You’re looking for the most obvious pattern in the data
- You want a clear narrative: “Here’s the problem period”
- Your audience doesn’t care about statistical nuance
- You’ve got time to debug potential code issues
Choose Claude 4.5 when:
- You need comprehensive, audit-ready analysis
- Statistical rigor matters (especially for reports that’ll be scrutinized)
- You want to catch problems that aren’t immediately obvious
- Code reliability is critical (production environments, automated reporting)
- You’re building analysis that needs to scale
Honestly? The ideal scenario is using both. Let GPT-5.1 give you the quick read, then verify with Claude’s thorough approach. Think of it as getting a second opinion, except your second opinion runs in thirty seconds.
What This Means for Your Data Work
The bigger insight here isn’t about which AI won some imaginary competition. It’s that we now have access to fundamentally different analytical approaches at the click of a button.
Five years ago, running this kind of comparative analysis would’ve meant hiring two different analysts or spending hours switching between tools. Now? You can spin up both analyses simultaneously and see where they agree (probably the real signal) and where they diverge (probably worth investigating further).

The errors in GPT-5.1’s execution also highlight something important: AI-generated code still needs human oversight. You can’t just run these analyses and walk away. But you also can’t ignore how much faster they make the initial exploration phase.
How Livedocs Speeds Up This Whole Process
Quick tangent, because this matters if you’re actually going to try this yourself.
Livedocs is specifically designed for this kind of AI-powered data analysis. Instead of juggling different AI chat interfaces and copying code back and forth, it gives you an actual notebook environment where you can:
- Generate analysis notebooks using GPT, Claude, or other models
- See code execution in real-time with proper error handling
- Compare different model outputs directly
- Work with actual datasets (CSVs, Excel files, whatever)
- Share results with your team without the usual “send screenshot” dance
The platform essentially turns “I wonder what this data means” into a working analysis in minutes instead of hours. You upload your data, pick your AI model, describe what you need, and get back a full notebook with code, visualizations, and insights.
What makes it particularly useful for comparative work, like what I did here, is that you can literally run the same prompt through different models and see how they approach the problem differently. It’s like having multiple data scientists on call, except they respond instantly and don’t need coffee breaks.
For teams doing serious data work, that speed advantage compounds quickly. Instead of one person spending a day building an analysis, three people can explore three different angles in an hour, then compare notes. The bottleneck shifts from “can we analyze this?” to “which insight should we act on?”
The Uncomfortable Truth About AI Analysis
Here’s something nobody wants to admit: these AI models don’t actually “understand” your business. They’re incredible at finding patterns, running calculations, and presenting information, but they don’t know that January 24th was when your marketing campaign launched or that February’s numbers always look weird because of fiscal year-end adjustments.
That context? That’s still your job.
What surprised me most in this comparison wasn’t that the models gave different answers, it’s that both answers were technically correct. GPT-5.1 wasn’t wrong about that January 24-29 drop being significant. Claude 4.5 wasn’t wrong about those 20 problematic days existing. They just emphasized different aspects of the same underlying truth.
This is why the future of data analysis isn’t “AI replaces analysts.” It’s “AI handles the mechanical pattern-finding so analysts can focus on the why behind the numbers.”
Pattern Recognition vs. Comprehensive Coverage
The GPT vs. Claude comparison reveals a fundamental tradeoff in AI analysis: focus versus coverage.
GPT-5.1’s approach is cognitively easier to work with. Humans like clear narratives. “Revenue dropped 69% during this specific week” is a statement you can build an action plan around. But that clarity comes from narrowing the scope, sometimes to the point where you miss important context.
Claude 4.5’s comprehensive approach catches more edge cases but demands more interpretation. When you flag 20 different problem days spread across six weeks, you’re not giving management a simple story, you’re giving them homework. But you’re also giving them a complete picture.
In my experience, the best data analysts naturally do both. They start broad (Claude’s approach) to understand the full landscape, then zoom in (GPT’s approach) to create actionable insights. The difference now is that AI can do that first pass in seconds instead of hours.
When the Models Agree
Both models identified revenue problems, that’s the good news. Your data’s not lying to you in ways that completely fool AI analysis.
But the disagreement about which problems matter most is fascinating. GPT says “focus here” while Claude says “these 20 days all need attention.” In some ways, that’s more valuable than if they’d given identical answers, because now you know where to dig deeper.
When two sophisticated AI models disagree about emphasis, that’s usually a sign that the underlying data has multiple valid interpretations. Maybe that January 24-29 period was an acute crisis, but it happened against a backdrop of chronic underperformance. Both can be true.
This is why comparative analysis, running the same question through different AI models, is becoming standard practice for serious data work. It’s not about finding “the right answer.” It’s about understanding the range of possible interpretations before you commit to a strategy.
The Future’s Already Here
William Gibson said that about technology in general, and it’s particularly true for AI-powered data analysis right now.

Some companies are already using multiple AI models in parallel for every analysis, treating disagreement as a feature rather than a bug. Others are still debating whether to adopt AI tools at all. The gap between those two groups is going to get uncomfortable pretty quickly.
Because here’s the thing: this technology isn’t getting slower or more expensive. It’s getting faster and cheaper. The analysis I ran for this article would’ve cost hundreds in API credits a year ago. Today? Pennies. Tomorrow? Effectively free.
The competitive advantage isn’t in having access to AI anymore, everyone has access. It’s in knowing how to use it effectively, understanding its limitations, and interpreting its outputs intelligently.
What We Actually Learned
Strip away all the technical details and model comparisons, and here’s what matters:
Different AI models will give you different answers to the same question.
Not because one’s wrong, but because they prioritize different analytical approaches. GPT-5.1 looks for focused narratives; Claude 4.5 does comprehensive scans. Both have value.
Technical execution matters as much as analytical insight.
Claude’s cleaner code execution gives it an edge in production environments, even if GPT’s focused approach might be more immediately actionable for stakeholders.
The real power is in comparative analysis.
Don’t just ask one AI, ask two or three, then look for patterns in their answers. Where they agree is probably signal. Where they disagree is probably worth investigating.
AI speeds up exploration, not decision-making.
These tools get you to insights faster, but they don’t eliminate the need for human judgment about what those insights mean and what to do about them.
Final Thoughts
So what do you actually do with this information?
If you’re working with data regularly, start experimenting with comparative analysis. Pick a dataset you know well and run it through different AI models, GPT, Claude, whatever else catches your interest. See how they approach the same problem differently.
Pay attention to where they agree (probably important) and where they disagree (definitely interesting). Use those disagreements as launching points for deeper investigation, not as reasons to distrust the tools.
And maybe most importantly: remember that these AI models are really, really good at finding patterns in data. They’re not as good at understanding why those patterns matter to your specific business. That last mile, turning insights into action, that’s still on you.
AI gives you the “what.” You still need to figure out the “why” and the “what now.” But man, getting to that “what” sure is faster than it used to be.
The best, fastest agentic notebook 2026? Livedocs.
- 8x speed response
- Ask agent to find datasets for you
- Set system rules for agent
- Collaborate
- And more
Get started with Livedocs and build your first live notebook in minutes.
- 💬 If you have questions or feedback, please email directly at a[at]livedocs[dot]com
- 📣 Take Livedocs for a spin over at livedocs.com/start. Livedocs has a great free plan, with $10 per month of LLM usage on every plan
- 🤝 Say hello to the team on X and LinkedIn
Stay tuned for the next article!
Curious about running your own comparative AI analysis? Check out platforms like Livedocs that let you test different models side-by-side with your actual data. The future of data work isn’t choosing one AI over another—it’s learning to use all of them strategically.
Ready to analyze your data?
Upload your CSV, spreadsheet, or connect to a database. Get charts, metrics, and clear explanations in minutes.
No signup required — start analyzing instantly

