Top 10 Pandas Functions for LLM Development
In the age of AI and Large Language Models (LLMs), the foundation of success is still data. Whether you’re fine-tuning a model, feeding structured datasets into embeddings, or analyzing outputs from GPT-like systems, your ability to manipulate, clean, and reshape data with Pandas is critical. Pandas isn’t just a beginner’s library anymore, when used right, it’s a powerhouse for LLM workflows.
In this guide, we’ll go through 10 advanced yet essential Pandas commands, complete with code examples, detailed explanations, and real-world LLM/AI use cases.
Also, I am using Livedocs for this tutorial. Livedocs has lot of useful feature for data dashboard, especially its powerful live feature, so sign up here.
Or if you prefer to view the example here directly, access it here.
Once you have your data file ready, let’s get started!
—
1. The Fundamentals
The first one we have to consider it’s the ability to view and read data, depends on the type of data, these are the command we will be using:
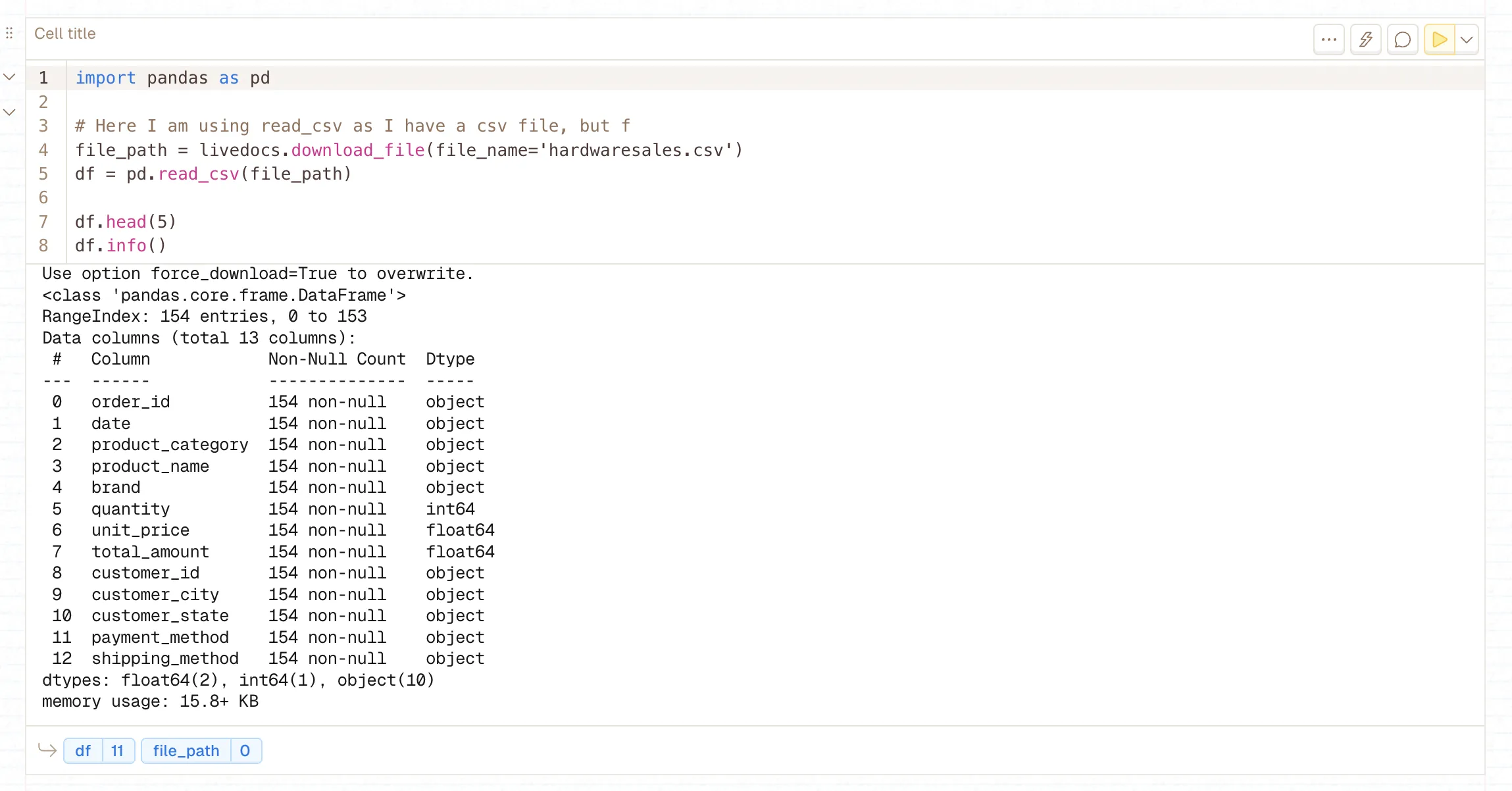
df.read_csv()
Reads a CSV file into a Pandas DataFrame. This is the primary entry point for loading structured data into your LLM preprocessing pipeline. Supports various encoding formats, separators, and parsing options essential for handling diverse text datasets.
LLM Use Cases:
- Loading conversational datasets, prompt-response pairs, or fine-tuning data
- Quickly inspecting data structure before preprocessing
- Understanding data types and memory usage for large text corpora
Pro Tips:
- Use df.head(10) for larger datasets to spot patterns
df.info()reveals null values and data types, crucial for text preprocessing- For large files, use chunksize parameter:
pd.read_csv('large_file.csv', chunksize=10000)
—
2. Handling missing data
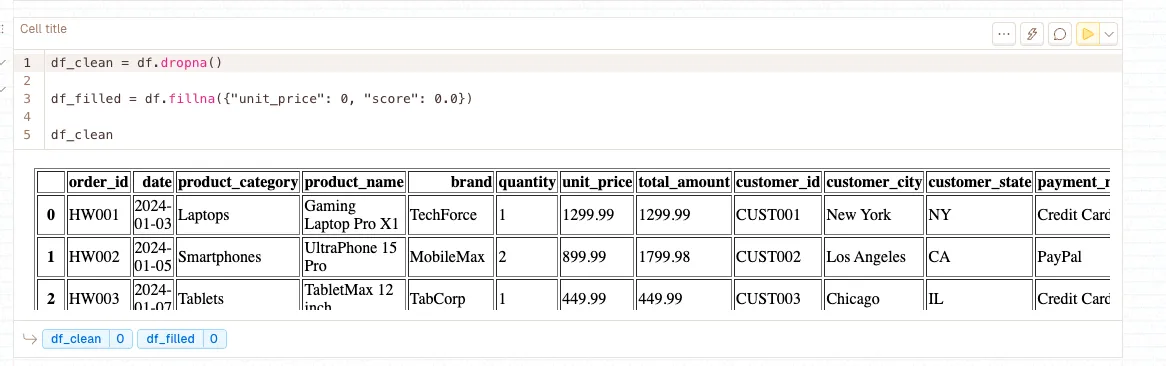
df.dropna()
Removes rows or columns containing missing values (NaN). Essential for maintaining data quality in LLM training, as missing values can cause tokenization errors and inconsistent model behavior. Supports flexible removal strategies including threshold-based dropping.
df.fillna()
Replaces missing values with specified alternatives. More nuanced than dropping data entirely, allowing you to preserve dataset size while handling missing information intelligently. Critical for maintaining training data volume while ensuring consistency.
LLM Benefits:
- Prevents training on incomplete examples that could confuse the model
- Maintains dataset consistency for batch processing
- Avoids tokenization errors from None/NaN values
—
3. Group By & Aggregations
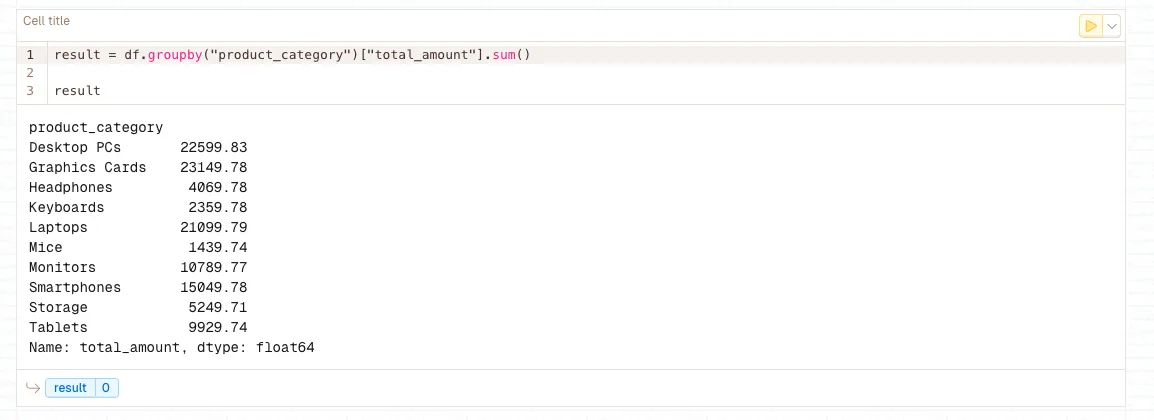
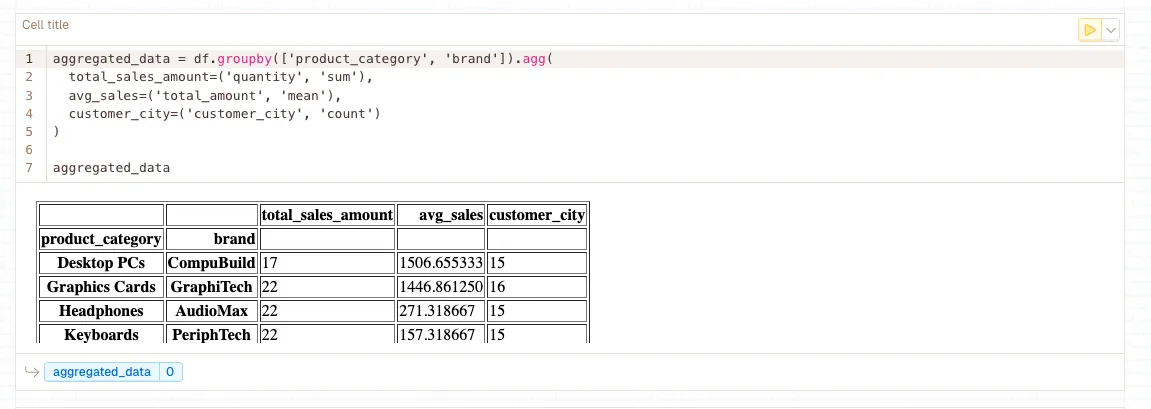
df.groupby()
Groups DataFrame rows by one or more columns and applies aggregation functions. Fundamental for analyzing data distributions, computing statistics by category, and understanding dataset characteristics. Essential for identifying data imbalances and creating stratified sampling strategies in LLM workflows.
LLM Applications:
- Balancing training data across different categories/intents
- Analyzing conversation patterns and dialogue flows
- Identifying data imbalances that could bias model training
- Computing statistics for dataset quality assessment
—
4. Convert Categorical Variables to Dummy Variables
pd.get_dummies()
Converts categorical variables into binary indicator columns (one-hot encoding). Each unique category becomes a separate binary column with 1/0 values. Critical for converting text-based categories into numerical features that can be used for conditional generation, multi-task learning, or as input features for classification models.
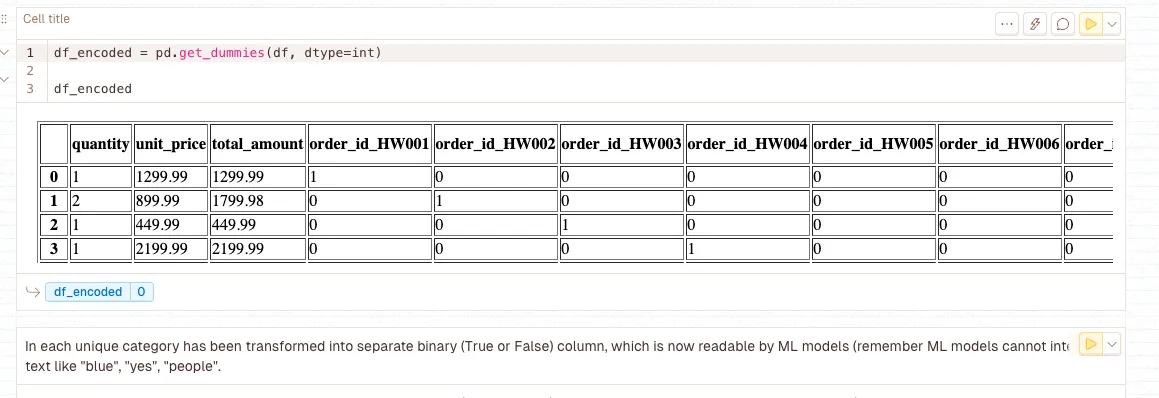
LLM Significance:
- Creates numerical features for metadata that can be used in model training
- Enables conditional generation based on task types or domains
- Facilitates multi-task learning setups
- Useful for creating balanced sampling strategies
—
5. Apply Custom Functions with Lambda
df.apply(lambda)
Applies a custom function to each row or column of a DataFrame. Lambda functions provide inline, anonymous function definitions perfect for simple transformations. This is the most flexible tool for custom text preprocessing, feature engineering, and applying complex transformations that aren’t available as built-in Pandas methods.
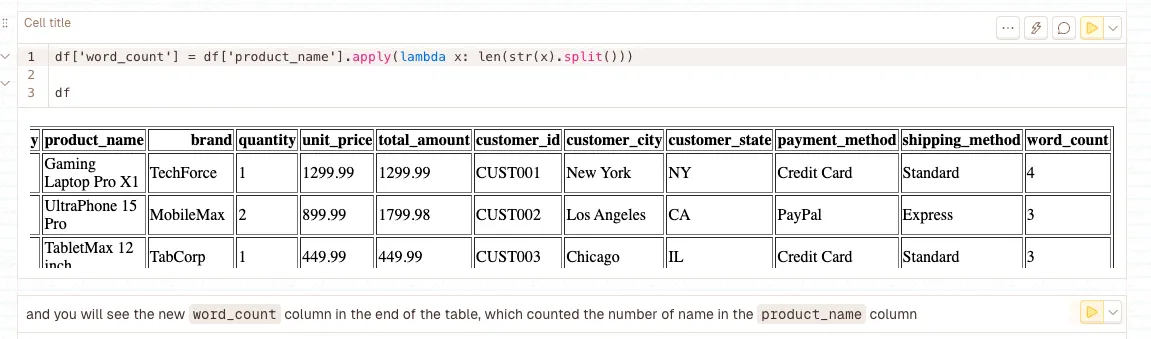
LLM Power Applications:
- Custom tokenization and text normalization
- Feature extraction for data filtering and selection
- Computing text complexity metrics
- Applying prompt templates dynamically
—
6. Convert to NumPy Arrays and Dictionaries
df.to_numpy()
Converts DataFrame values to a NumPy array, removing column labels and index information. Essential for interfacing with machine learning libraries like PyTorch and TensorFlow, which expect NumPy arrays as input. Provides memory-efficient, homogeneous data structures optimal for numerical computations and model training.
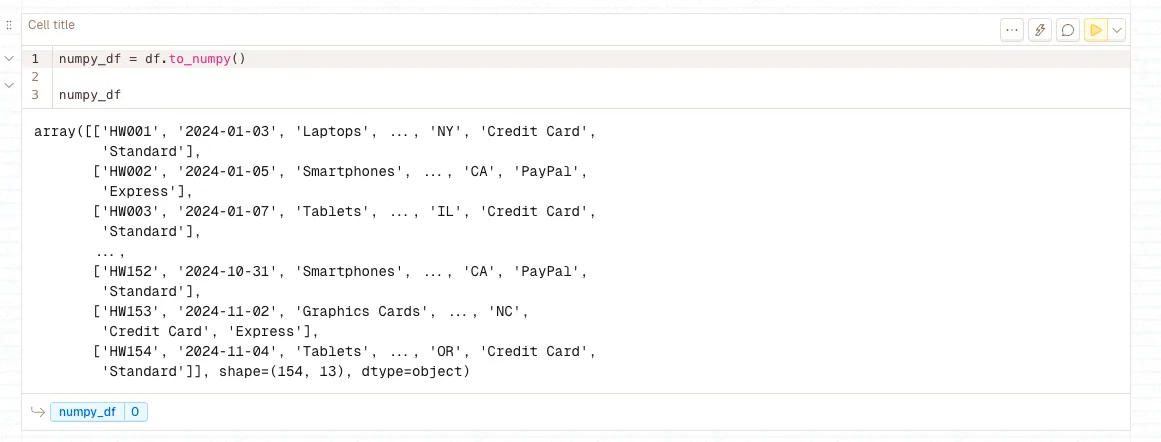
LLM Integration Benefits:
- NumPy arrays integrate seamlessly with PyTorch/TensorFlow
- Dictionary format perfect for JSON datasets and API responses
- Efficient memory usage for large text datasets
- Easy conversion for tokenizer inputs
—
7. Expand Tokens, Embeddings, and Lists
df.explode()
Transforms each element of a list-like column into a separate row, duplicating other column values. Invaluable for expanding tokenized text, attention weights, or any list-structured data stored in DataFrame cells. Essential for token-level analysis and converting nested data structures into flat, analyzable formats.
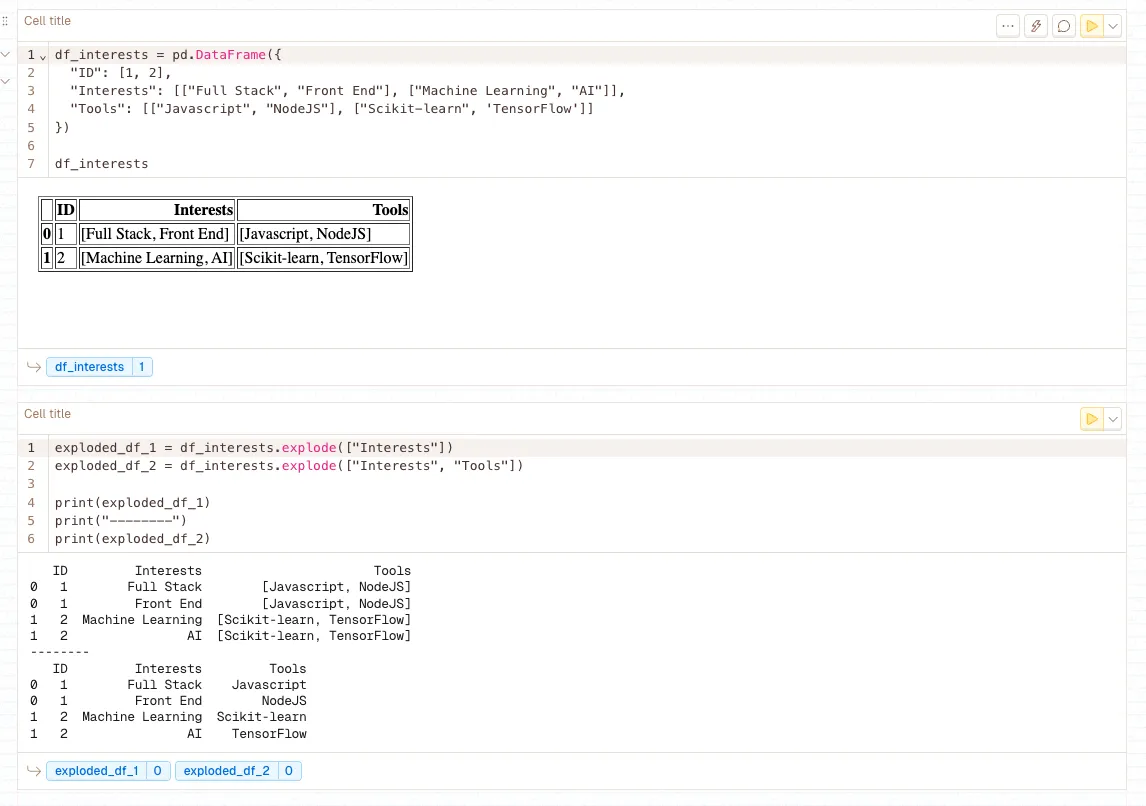
LLM-Specific Applications:
- Token-level analysis and statistics
- Expanding pre-computed embeddings for similarity analysis
- Processing attention weights and model outputs
- Creating token-level datasets for fine-grained tasks
—
8. Quick Data Sampling
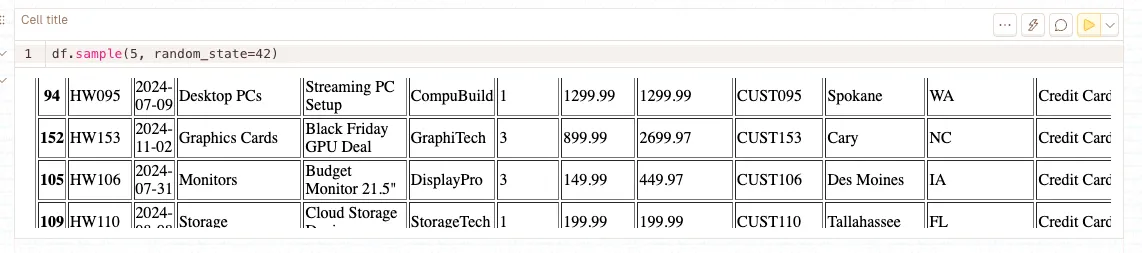
df.sample()
Randomly selects a subset of rows from the DataFrame. Supports various sampling strategies including fixed numbers, percentages, and weighted sampling. Crucial for creating development sets, testing preprocessing pipelines on manageable data sizes, and implementing data augmentation strategies without processing entire datasets.
Here we randomly selected 5 samples using the command df.sample(5, random_state=42)
LLM Development Benefits:
- Create representative development sets quickly
- Test preprocessing pipelines on smaller datasets
- Maintain class/task balance in samples
- Generate diverse evaluation sets
—
9. Quick Visualization
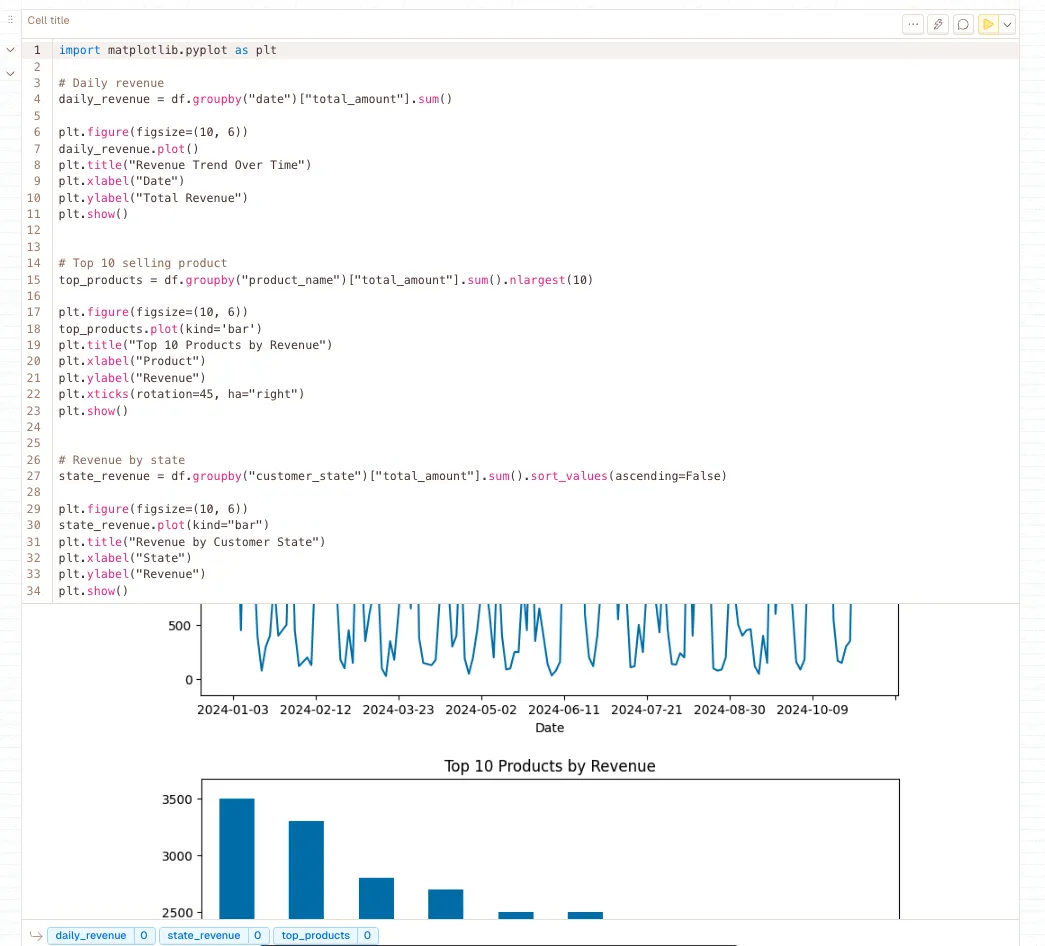
df.plot()
Creates basic plots directly from DataFrame columns. Supports various plot types (line, bar, scatter) with minimal syntax. Invaluable for quick data exploration, trend analysis, and identifying patterns in LLM training metrics without switching to external plotting libraries.
df.hist()
Generates histograms showing the distribution of numerical values. Essential for understanding data distributions, identifying outliers, and assessing data quality. Particularly useful for analyzing text length distributions and quality score patterns in LLM datasets.
df.boxplot()
Creates box plots showing data distribution quartiles, median, and outliers. Excellent for comparing distributions across categories and identifying data quality issues. Crucial for spotting problematic data points that could negatively impact model training.
LLM Quality Control:
- Identify outliers in text length that might break tokenizers
- Visualize data quality distributions across different sources
- Monitor data collection patterns and trends
- Spot potential biases in categorical distributions
—
10. Reshaping Data
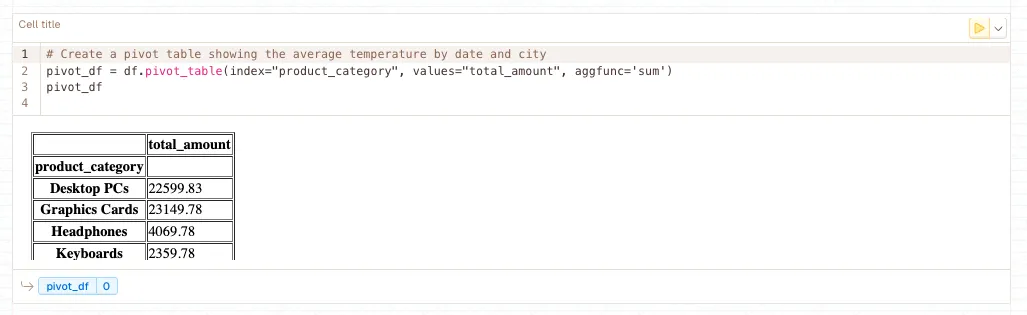
df.pivot_table()
Reshapes data by rotating unique values from one column into multiple columns, creating a spreadsheet-style pivot table with aggregated values. Essential for transforming long-format data into wide-format matrices, comparing metrics across different dimensions, and creating summary tables for analysis and reporting.
LLM Applications:
- Transform conversational data for sequence modeling
- Create feature matrices for metadata analysis
- Reshape evaluation results for comprehensive reporting
- Prepare data for cross-validation splits
—
11. Reshaping Fine-Tuning Data
df.to_json()
Exports DataFrame to JSON format with various orientation options. The orient='records' parameter creates a list of dictionaries (one per row), while lines=True creates JSONL format where each line is a separate JSON object. This is the standard format for most LLM fine-tuning pipelines and API-based training systems.

Fine-Tuning Optimization:
- JSONL format is standard for most LLM training pipelines
- Include metadata for data provenance and quality tracking
- Validate format compatibility before expensive training runs
- Create train/validation splits with proper randomization
—
Final Thoughts
And that’s it, you’ve just learned the top 10 Pandas functions for LLM. Mastering these Pandas operations will significantly accelerate your LLM development workflow.
From initial data exploration to final fine-tuning preparation, these functions form the foundation of efficient data manipulation. Remember to always validate your data transformations and maintain data quality throughout your preprocessing pipeline.
The fastest way to build a live dashboard in 2026? Livedocs.
- Instant data connections
- Drag-and-drop editor
- Real-time updates
- Easy sharing
Get started with Livedocs and build your first live dashboard in minutes.
—
- 💬 If you have questions or feedback, please email directly at a[at]livedocs[dot]com
- 📣 Take Livedocs for a spin over at livedocs.com/start. Livedocs has a great free plan, with $10 per month of LLM usage on every plan
- 🤝 Say hello to the team on X and LinkedIn
Stay tuned for the next tutorial!
Ready to analyze your data?
Upload your CSV, spreadsheet, or connect to a database. Get charts, metrics, and clear explanations in minutes.
No signup required — start analyzing instantly

